Generation
Target: find data distribution
x 是一个图片 ( a high-dimensional vector)
Before GAN
Target:使用一个分布 gaussian mixture model,此时 means and variances of this model
- Given a data distribution
(We can sample from it) 未知,但是可以 sample from it. (就是从已有的 database中sample出来一些) - We have a data distribution
parameterized by We want to find
such that close to - Sample {
} from and compute - Find
maximizing the Object Function
Object Function:Maximum Likelihood Estimation (最大似然估计)
要使
$$\begin{aligned}
\theta^* &= \arg\mathop{\max}\limits_{\theta}F(\theta) \tag{2} \
&= \arg\mathop{\max}\limits_{\theta}\sum_{x=1}^mlog(P_G(x^i;\theta)) \
&\approx \color{red}\arg\mathop{\max}\limits_{\theta}E_x\sim_{P_{data}(x)}(log(P_G(x;\theta)))\
&= \color{red}\arg\mathop{\max}\limits_{\theta} (\int_x P_{data}(x)log(P_G(x;\theta))dx - \int_x P_{data}(x)log(P_{data}(x))dx) \
&= \arg\mathop{\max}\limits_{\theta}\int_xP_{data}(x)log(P_G(x;\theta)/P_{data}(x))dx \
&= \arg\mathop{\min}\limits_{\theta} KL Div(P_{data}||P_G)
\end{aligned}$$
即: Maximum Likelihood Estimation
因此 对于 Generator 的目的就是
这里存在一个问题: How to define general
对于 Nerual Network),即
Using GAN
GAN 是如何处理这个问题的呢? (Generator)
GAN 采用了一个 NN 来拟合
To learn the generator’s distribution
,we define a prior on input noise variables , then represent a mapping to data space as ,where G is a differentiable function represented by a multilayer perceptron with parameters .
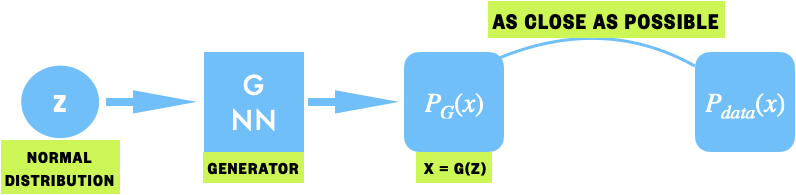
prior distribution
根据上面可知,它的 Object Function (loss) 是某种 Divergence, 即
而且目的为是这种散度最小,即
关键就是如何计算这种 Divergence?
How to Compute Divergence (Discriminator) ?
对于
We alse define a second multilayer perceptron
that outputs a single scalar. D(x) represents the probability that x came from the data rather that . We train D to maximize the probability of assigning the correct label to both training examples and samples from G.

Object Function For D
When train D, Gis fixed:
即
式(3)如何解释呢?
- 当 x 从
sample 出来的时,那就使 scalar(D(x)) 越大越好(因为它是真实的) - 当 x 从
sample 出来时, saclar(D(x))越小越好,即1-D(x)越大越好(因为它是Generator出来的的)
上面我们讲到,generator的目的使
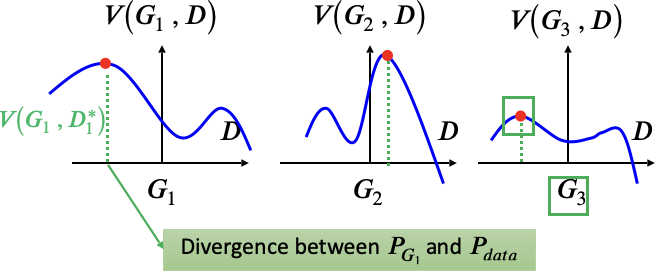
证明 V(G,D) 等同于 JS-Divergence
fixed G, 求解
Given x,
使 maximum
简化为Assumed:
and $$\begin{aligned}
&L(D) = alogD + blog(1-D) \
&\frac{dL(D)}{dD} = a/D + b/(1-D)(-1) = 0\
& D^ = a/(a+b) \tag{6}\end{aligned}$$
For any (a,b)
, function achieves its maximum in [0,1] at 将
带入到式(3)中,有:
计算
上式就等同于:
其中
Algorithm
- Initialize generator and discriminator
- In each training iteration:
- Fix G, update D
- Fix D, update G
Procerss
实际上:
initialize
In each training iteration
Training D, repeat K times
- sample m examples{
} from database - sample m examples{
} from prior distribution - get generated data {
} via - fixed
,update to maximize:
- sample m examples{
Training G, only once
- sample m examples{
} from prior distribution - fixed
,update to minimize:
- sample m examples{
实际上,在 Training G 时,采用的是:
- 本文标题: Theory behind GAN
- 本文作者:codeflysafe
- 创建时间:2020-06-15 12:56:39
- 本文链接:https://codeflysafe.github.io/2020/06/15/2020-06-15-Theory-behind-GAN/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!