缓存一致性问题
同一个数据在不同的缓存中看到的值是不同的,这就是缓存一致性问题
考虑下面一个程序(cache_consistency/SumTest.java)
1 | package cache_consistency; |
缓存一致性问题展示:如果没有缓存一致性
| 动作 | t0(thread) 高速缓存 | t1(thread1 )的高速缓存 | 共享内存 |
|---|---|---|---|
| 初始状态 | - | - | sum = 0 |
| t0 读入 sum | sum = 0 | - | sum = 0 |
| t0 将3累加到sm | sum = 3 脏 | - | sum = 0 |
| t1 读入sum | sum = 3 脏 | sum = 0 | sum = 0 |
| t1 将7累加到sum | sum = 3 脏 | sum = 7 脏 | sum = 0 |
缓存的写回策略有两种:写回法和直写法,上图是写回法可能出现的一种情况
下面是直写法,可能会遇到的一种情况:
| 动作 | t0(thread) 高速缓存 | t1(thread1 )的高速缓存 | 共享内存 |
|---|---|---|---|
| 初始状态 | - | - | sum = 0 |
| t0 读入 sum | sum = 0 | - | sum = 0 |
| t0 将3累加到sm | sum = 3 | - | sum = 3 |
| t1 读入sum | sum = 3 脏 | sum = 3 | sum = 3 |
| t1 将累加到sum | sum = 3 脏 | sum = 10 脏 | sum = 10 |
此时,内存中的值是正确的,但是缓存中的值是不同的
因此,为了满足高速缓存值的一致性,需要缓存一致性的支持。缓存一致性需要两种需求:
写传播需求 和 事务串行化
写传播
是指,需要将一个在高速缓存中修改的值同步传播到其它高速缓存中
事务串行化
事务串行化,分为读写和写写
写写之间的串行化
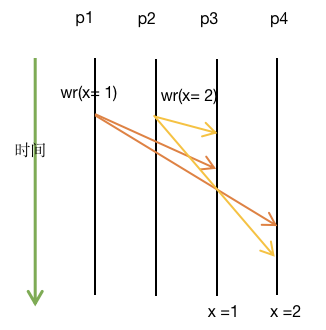
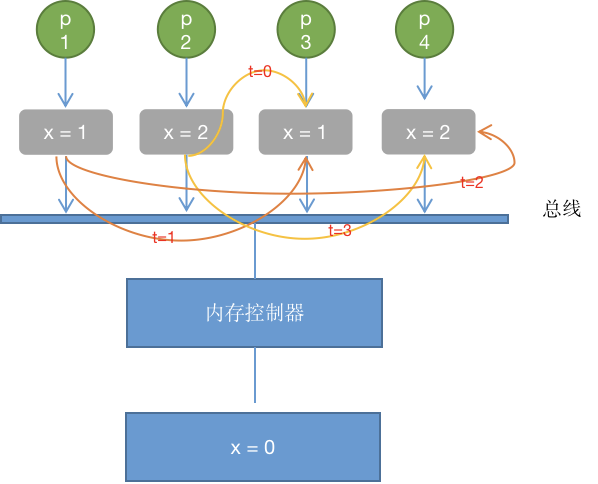
如上图所示,在写回的缓存策略下,如果只有写传播而没有事务串行化,P1,P2,P3,P4 是四个处理器,P1在其缓存中写入1,与此同时P2在其缓存中写入2,然后两者同时传播到其它高速缓存中,将可能得到不同的结果(如下图所示)。
读写之间的串行化
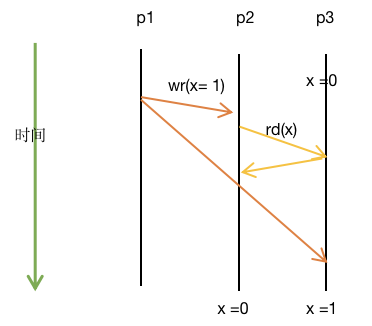
P1,P2,P3是三个处理器,P1将其高速缓存中的x修改为1,同时向P2,P3传播此修改。此时P2读取P3缓存内的x,将其作为新的x。结果是 P2认为新的x=0, P3认为新的x=1
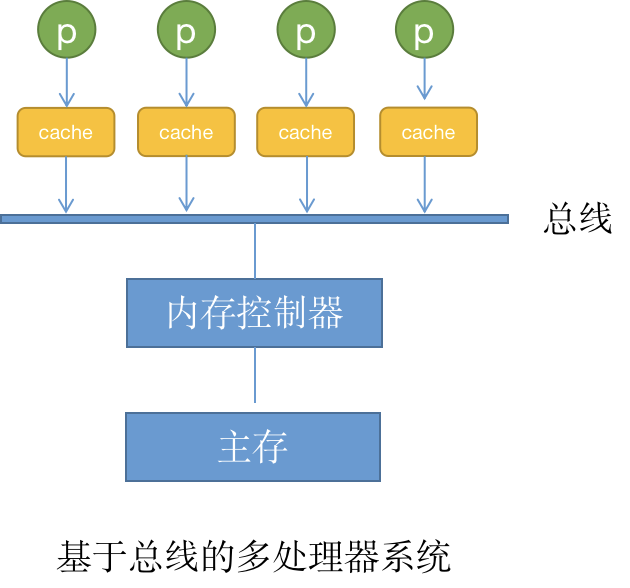
基于总线的多处理器系统
几个关于缓存的名词
缓存命中
写回: 先写到高速缓存中,直到缓存要被淘汰了,再写回到下一层中(比如内存)
直写: 写到高速缓存中后,紧接着写回到下一层中(比如内存)
缓存未命中
写分配: 缓存未命中时,加载低一层中的块到高速缓存中,然后更新这个缓存。 通常与写回策略一起使用
非写分配:避开高速缓存,直接将这个字写到低一层中。通常与直写配合使用
总线
总线分为3中,命令、地址和数据
命令总线:传递读或写的总线指令
地址总线:传递向存储器请求数据或者向存储器写入数据时该数据的地址
数据总线:写时,将数据传递给存储器,读时,从存储器返回数据
在写回策略时,一个读缺失,将发出一个读请求
基于写分配策略时,一个写缺失,也会发出一个读请求
当一个缓存块要写回到低一层中,将发出一个写请求
总线事务
总线事务分为三个阶段
总线仲裁
总线仲裁是为了避免来自不同处理器的请求在总线上发生碰撞。选择不同的仲裁策略(链式查询、计数器定时查询、独立请求模式、分布式仲裁),将总线的控制权交给不同的端口
命令传输
把目标地址(主存地址或者I/O端口)放到值直线上
数据传输
读操作,就将数据从存储器中放入总线,写操作,从缓存中放入到总线
一致性控制器
分离式事务总线系统,一致性控制器加到处理器侧与存储器侧(内存控制器里可以有对应的侦听器,来侦听总线事务)。里面有个侦听器,监听每一个总线事务,用来查询是否有数据块与该总线事务有关,然后做出相应的反应

写回缓冲区, 从缓存中发出去的数据会先被放在一个叫做写回缓存区的数据对队列
缓存一致性协议
缓存一致性协议有很多种,如专门针对“写直达”的缓存一致性协议,还有针对写回的MSI、MESI、MOESI协议,这里记录的是MESI协议
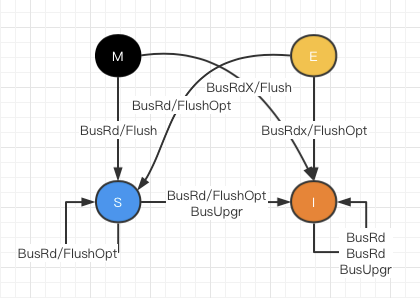
缓存请求和总线侦听的请求
处理器的缓存请求:
- PrRd: 处理器请求从缓存块中读出
- PrWr: 处理器请求向缓存块写入
总线侦听请求:
- BusRd: 总线侦听到一个来自另外一个处理器的读出缓存请求
- BusRdX: 总线侦听到一个来自另外一个尚未取得该块的处理器的“读独占”(或者写)缓存请求
- BusUpgr: 侦听到一个要向其它处理器缓存已经拥有的缓存块上写入的请求(缓存传播)
- Flush: 总线侦听到一个缓存块被另外一个处理器写回到主存的请求
- FlushOpt: 侦听到一整块缓存块被放置总线以提供给另一个处理器
缓存块的状态
每一个缓存块都分为以下几种状态:
Modified(M): 缓存块有效,并且与主存中的原始数据不同。
Exclusive(E): 缓存块是干净有效且唯一的
Shared(S): 缓存块是干净的,但是多个缓存块存在缓存
Invalid(I): 缓存块无效
它的有限状态机是:
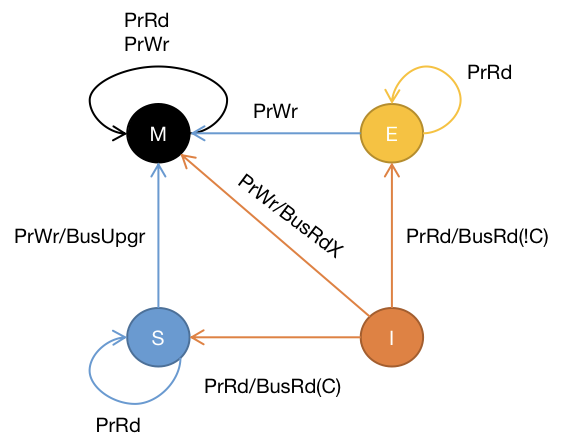
侦听到事务总线的状态机为:

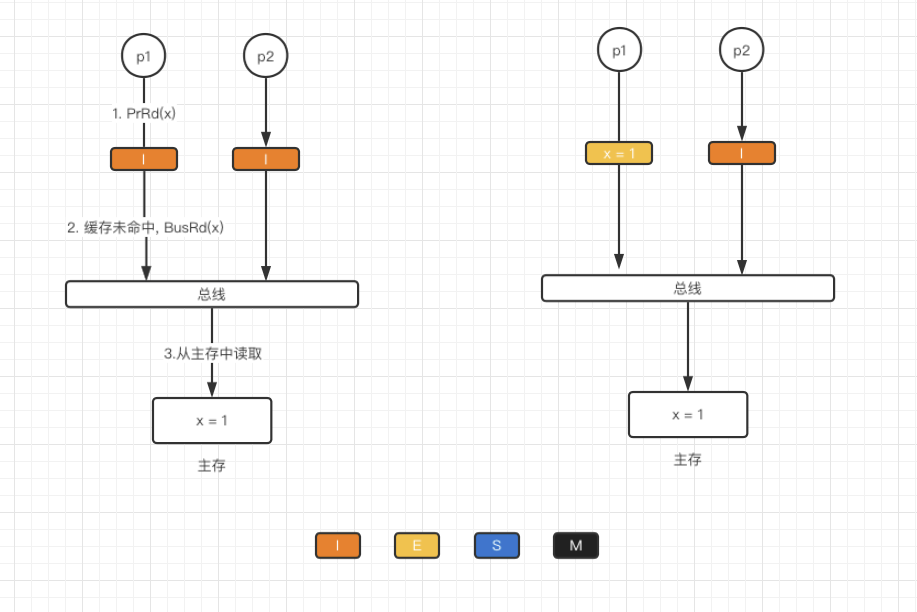
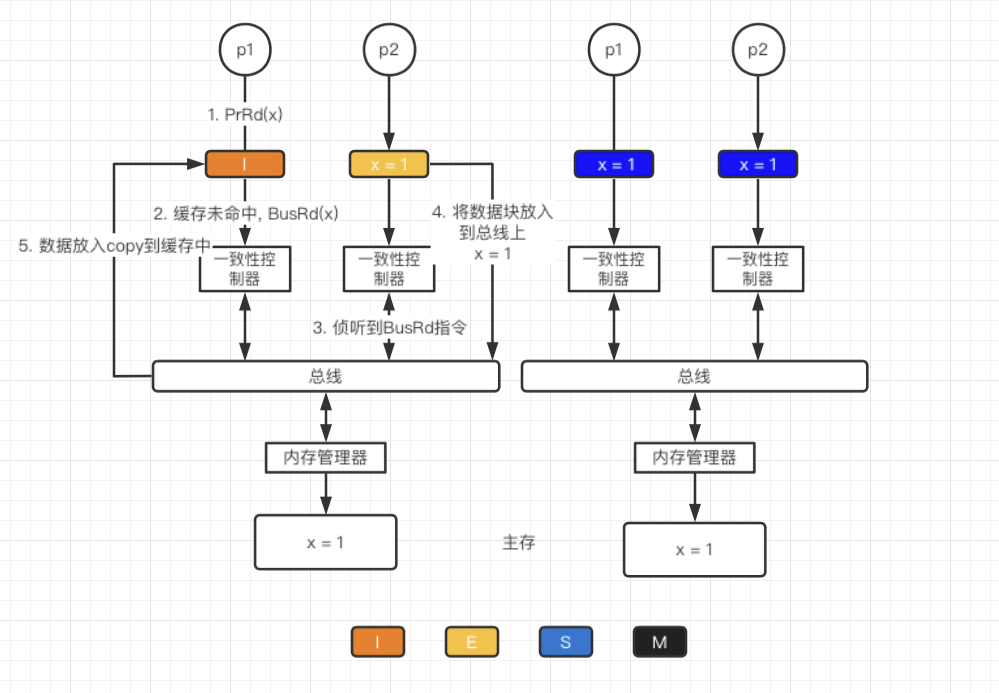
**I→E**
当前缓存块处于I状态,处理器发出PrRd(x), 此时缓存未命中,总线监听到BusRd(x)请求.由于没有其它缓存块读取此数据,则将该缓存块状态置为E
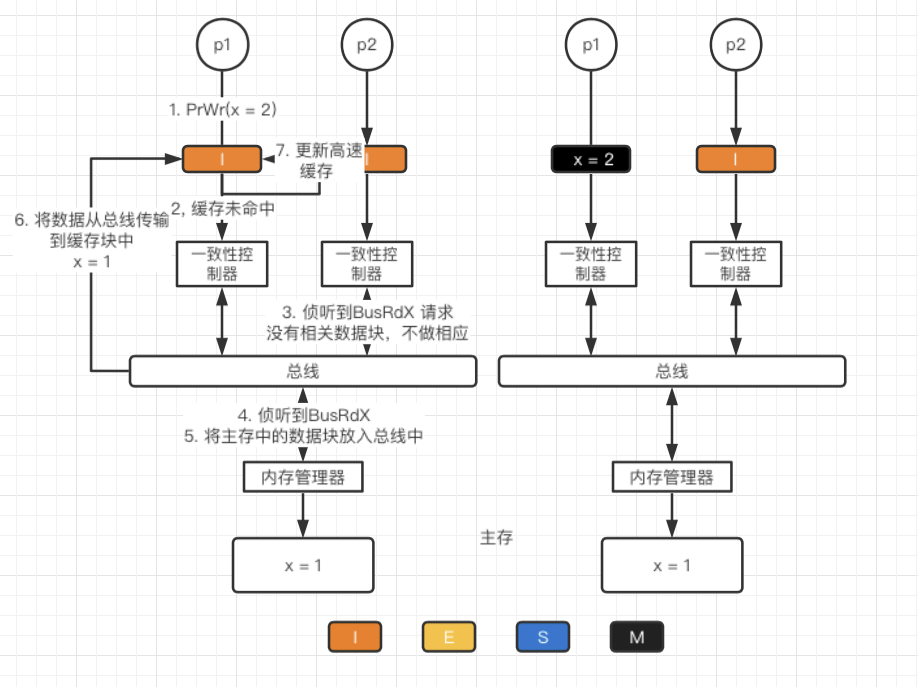
**I→M**
采用写分配方法,先从主存中加载数据块到缓存,然后在更新高速缓存(此时主存数据还未更新)
**I→S/ E→S**
MESI协议,提供了缓存到缓存的传输来优化性能,即干净且有效的缓存可以通过其它缓存的拷贝来提供而不仅是从主存中获取
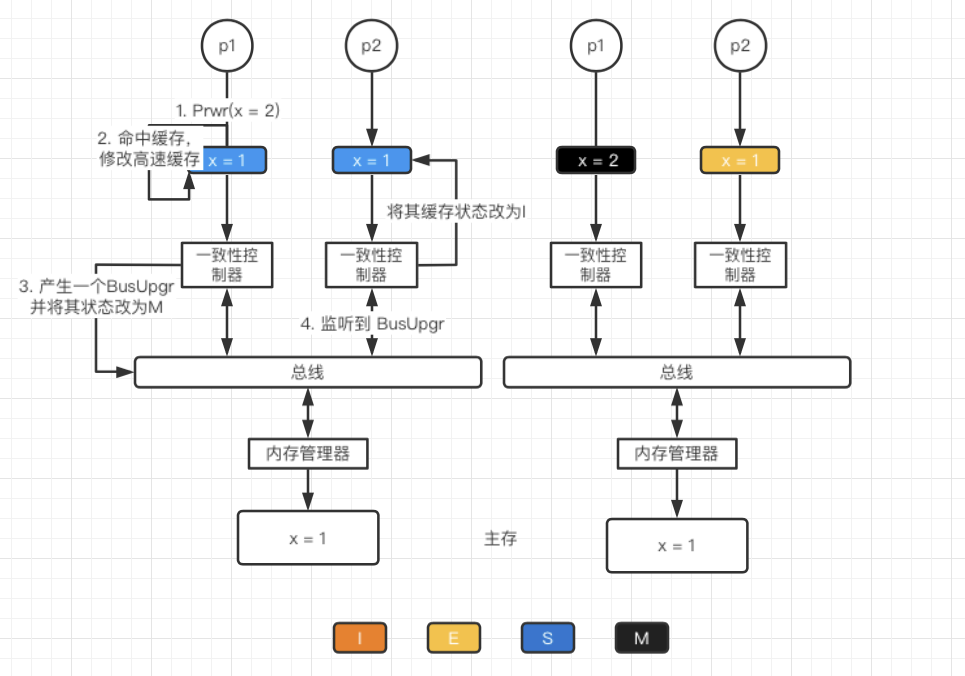
**S→I/S→M**
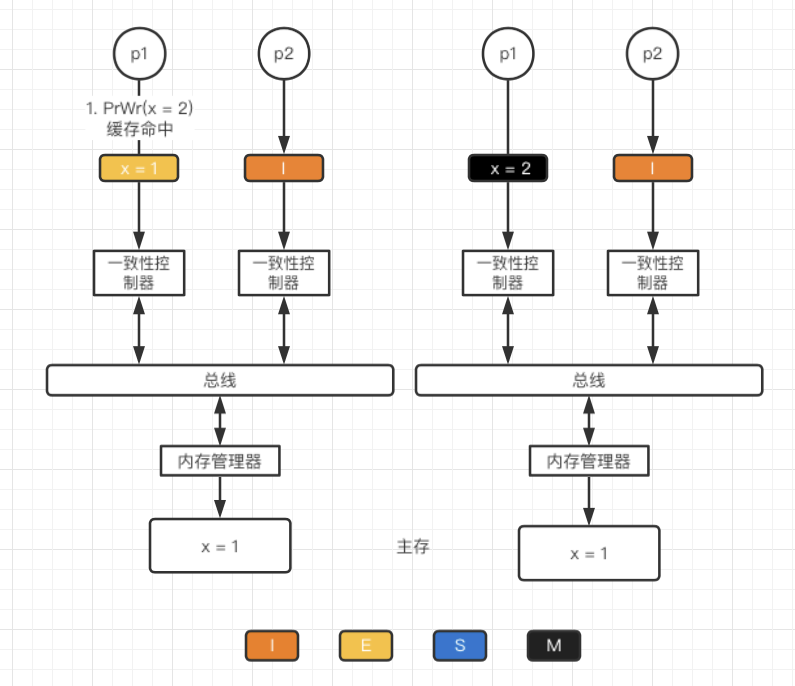
**E→M**
采用的是写回策略,缓存命中,直接修改高速缓存。
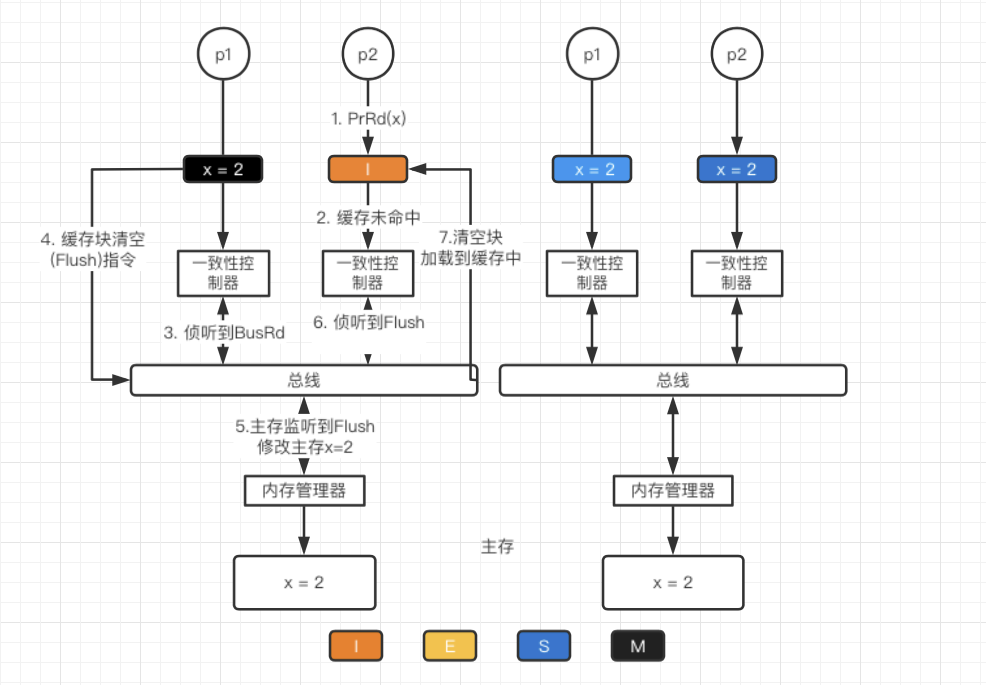
**M→S/I→S**
MESI 协议的优化
问题背景:Stall 的产生
当处于S状态的处理器发出写请求时,会发出一个BusUpgr请求来无效化其它拷贝(其它处理器的缓存)。等其它处理器相应该请求后,该处理器的缓存状态变为M。这里面设计一个同步的问题,即处理器必须等到其它处理器相应无效后才能继续操作。
Since CPU 0 must wait for the cache line to arrive before it can write to it, CPU 0 must
**stall**for an extended period of time.

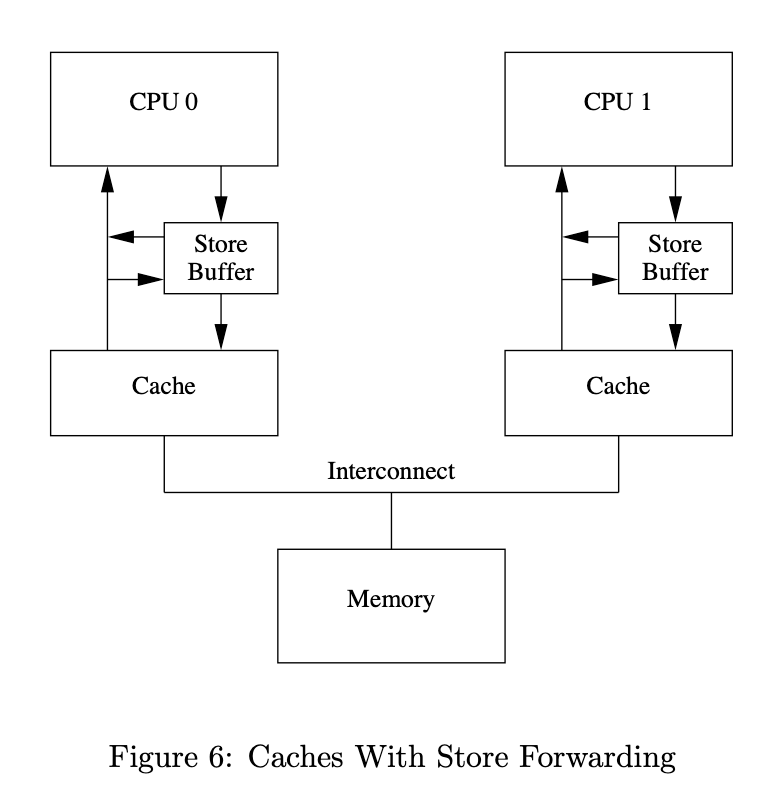
Store Buffer
一种阻止这种不必要等待的方式是,在处理器和cache之间增加一个Sotre Buffer
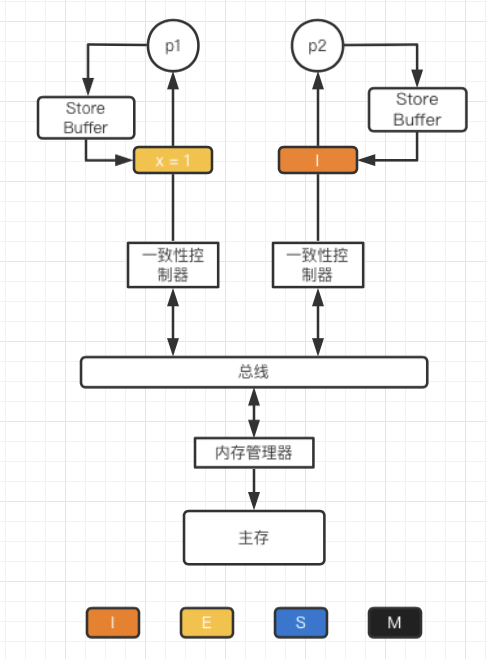

当处理器发出写命令后(PrWr), 处理器将要修改的数据写入到Store Buffer中,然后继续执行。当等到其它处理器响应完后,再将数据从Store Buffer更新到缓存中
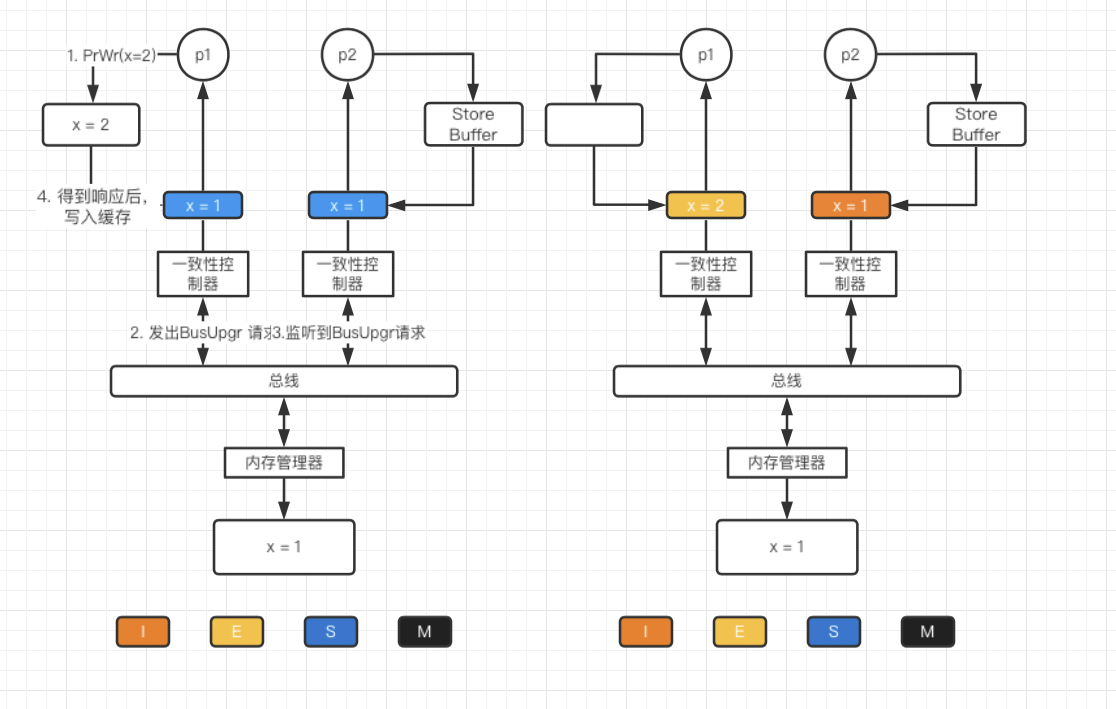
但是这里存在一个问题(cpu0执行)
1 | // a = 0, b = 0 |
由于 a = 1 指令未将其它缓存无效化,且不是立刻写入缓存而是将a=1放入Store Buffer, 因此当执行 b = a + 1时,此时a = 0, b = 1, 则assert(b == 2) fail
Store Forwarding(存储转发)
分析上面那个问题发现,数据存在两个copy,一个在缓存中,一个在Store Buffer中。由于缓存中存储的并不一定是最新的数据,这就造成了有可能将旧数据拿来运算的问题。解决这个问题的方法也很直观,就是在每次取数据时先去Store Buffer 寻找,然后再去缓存中读取,这就是“store forwarding“(存储转发)。
上面这个方法只是解决了在一个CPU中读取数据的问题,但是在并发条件下同样存在问题
1 | // 代码片段3 |
初始状态 a =0, b = 0, a 在cpu1 cache 中, b 在cpu0 cache 中, 两者的状态均属于 E 状态
cpu0 执行 foo函数, cpu1 执行 bar 函数
| 指令 | 动作 | cpu0 cache | cpu0 cache buffer | cpu1 cache | cpu1 cache buffer | main memory |
|---|---|---|---|---|---|---|
| - | 初始化 | E, b= 0 | E, a= 0 | a=0, b= 0 | ||
| cpu1 while(b==0) | cpu1 无 b, 发出PrRd(b)请求 | E,b= 0 | E,a=0 | a=0,b=0 | ||
| cpu0: a = 1 | cpu0 无 a, 发出 BusUpgr(a)请求 | E, b =0 | a= 1 | E,a = 0 | a=0,b=0 | |
| cpu0:b=1 | cpu0 执行 b = 1 | M b=1 | a=1 | E,a=0 | a=0,b=0 | |
| cpu1 收到PrRd(b)请求,循环结束 | S b= 1 | a=1 | S,b=1, E a= 0 | b=1,a=0 | ||
| cpu1: asser(a==1) | a≠ 0, fail | S b= 1 | a=1 | S b= 1 E a=0 | a=0,b=1 | |
| cpu1 收到 BusUpgr(a) | E a=1, S b = 1 | S b = 1, I a = 0 | a = 1, b = 1 |
出现这个问题的原因在于CPU不知道a, b之间的数据依赖,CPU0对a的写入走的是Store Buffer(有延迟),而对b的写入走的是Cache,因此b比a先在Cache中生效,导致CPU1读到b=1
时,a还存在于Store Buffer中。
Memory Barrier
对于上面的内存不一致,很难从硬件层面优化,因为CPU不可能知道哪些值是相关联的,因此硬件工程师提供了一个叫内存屏障的东西,开发者可以用它来告诉CPU该如何处理值关联性。我们可以在a=1和b=1之间插入一个内存屏障
1 | // 代码片段4 |
当CPU看到内存屏障smp_mb()时,会先刷新当前(屏障前)的Store Buffer,然后再执行后续(屏障后)的Cache写入。这里的”刷新Store Buffer”有两种实现方式: 一是简单地刷新Store Buffer(需要挂起等待相关的Cache Line到达),二是将后续的写入也写到Store Buffer中,直到屏障前的条目全部应用到Cache Line(可以通过给屏障前的Store Buffer中的条目打个标记来实现)。这样保证了屏障前的写入一定先于屏障后的写入生效,第二种方案明显更优.
Invalid Queue(失效队列)
失效队列的引入:
- stall
2.Store Buffer的大小是有限的
One reason that invalidate acknowledge messages can take so long is that they must ensure that the corresponding cache line is actually invalidated, and this invalidation can be delayed if the cache is busy,
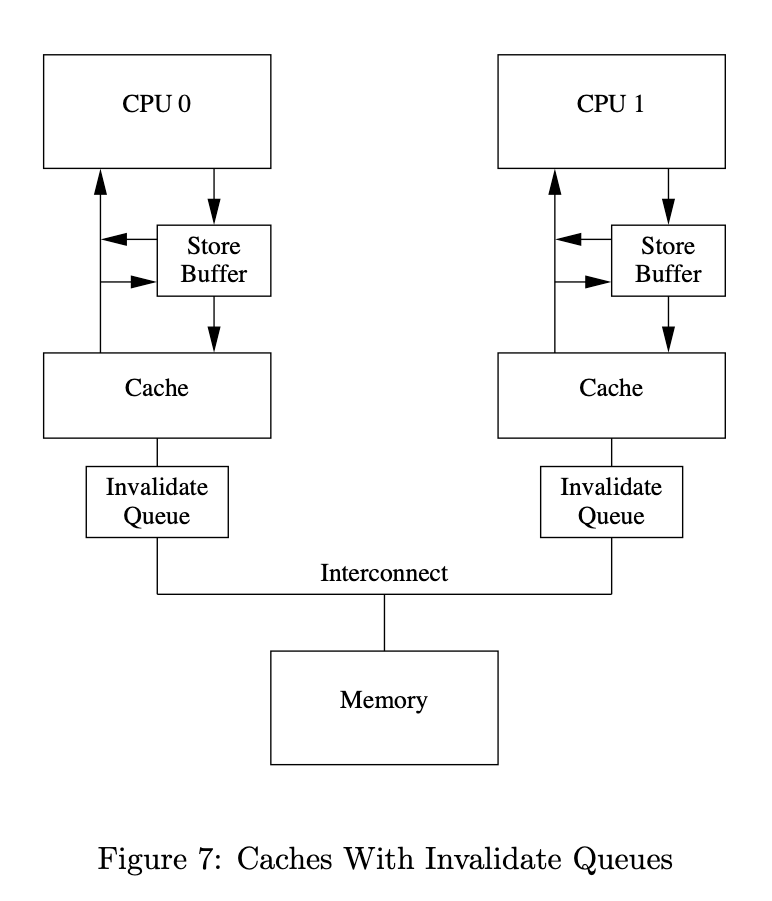
收到广播的CPU为了尽快响应 invalid ACK,所以就增加了一个失效队列,当收到其他CPU广播的invalid 消息后,不一定要马上处理,而是把放这个“失效队列里面”,然后就马上返回 invalid ack 。然后当自己有时间的时候再去处理失效队列里的消息,最后通过这种异步的方式,加快了CPU整个修改数据的过程。
读屏障(Read Memory Barrier)和写屏障(Write Memory Barrier)
1 | // 代码片段5 |
- 读屏障: 任何读屏障前的读操作都会先于读屏障后的读操作完成
- 写屏障: 任何写屏障前的写操作都会先于写屏障后的写操作完成
- 全屏障: 同时包含读屏障和写屏障的作用
foo函数只需要写屏障,bar函数需要读屏障。实际的CPU架构中,可能提供多种内存屏障,比如可能分为四种:
- LoadLoad: 相当于前面说的读屏障
- LoadStore: 任何该屏障前的读操作都会先于该屏障后的写操作完成
- StoreLoad: 任何该屏障前的写操作都会先于该屏障后的读操作完成
- StoreStore: 相当于前面说的写屏障
实现原理类似,都是基于Store Buffer和Invalidate Queue
指令重排 Instruction Reordering
重排序是指编译期和运行期间为了优化程序性能而对指令序列进行重新排序的一种手段
重排序的一个要求:无论如何重排序,单线程程序的执行结果都不会改变, 即遵守 as-if-serial
编译器和处理器不会对存在数据依赖关系的操作做重排序,数据依赖(参见流水线中的数据冲突)
写后读、读后写、写后写
可以是用一个DAG图表示
1 | // 代码片段5 |
如果上面这个程序发生了指令重拍
1 | b = 1; |
也可能给出错误的答案
应用
volatile
保持可见性, 禁止指令重拍
java中可以通过volatile关键字来保证变量的可见性,并限制局部的指令重排。它的实现原理是在每个volatile变量写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障,在每个volatile变量读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障来完成。
References
- 本文标题:缓存一致性
- 本文作者:codeflysafe
- 创建时间:2022-03-01 00:03:27
- 本文链接:https://codeflysafe.github.io/2022/03/01/consistency/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!