Bitcask 存储模型
Paper: Log-Structured Hash Table for Fast Key/Value Data
Achieving some of these is easy. Achieving them all is less so.
Bitcask 原来是用于记录Riak distributed database的历史。在Risk的集群中,每个node使用插件式的存储引擎,几乎所有key-value类型的存储引擎都可以作为单个node节点的存储引擎。这种内嵌式的存储引擎可以在不影响其它codebase的情况下提升和测试。
BitCask 的设计目标是:
- 读写低延迟 low latency per item read or written
- 高吞吐量,high throughput, especially when writing an incoming stream of random items
- 处理更大的数据 ability to handle datasets much larger than RAM w/o degradation
- 崩溃恢复容易并且不会丢失数据: crash friendliness, both in terms of fast recovery and not losing data
- 容易备份和存储 ease of backup and restore
- 一个相当简单并且容易理解的数据形式 a relatively simple, understandable (and thus supportable) code structure and data format
- predictable behavior under heavy access load or large volume
采用 hash table log merging, 有可能比 LSM-trees 更快
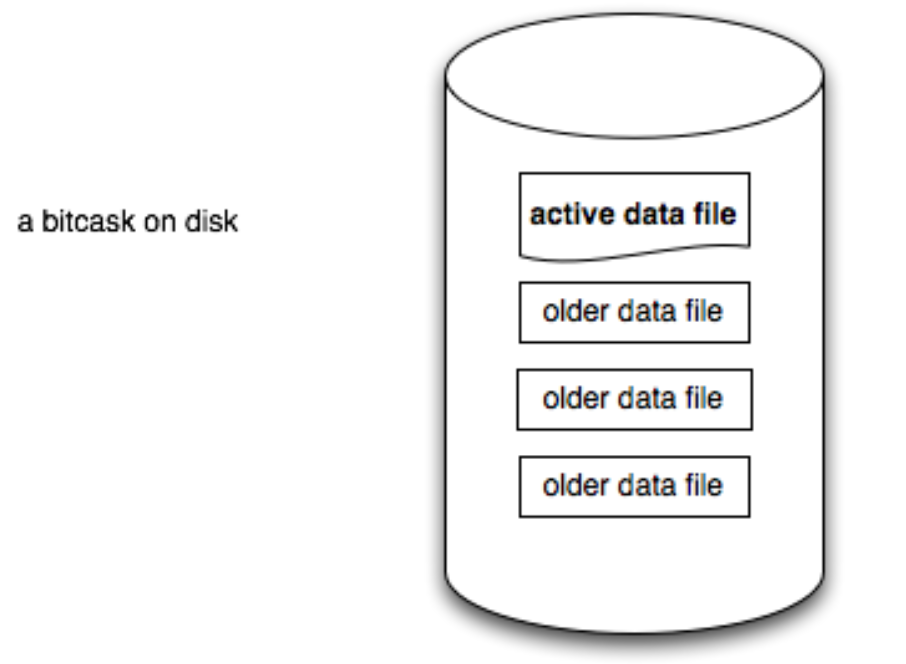
一个bitcask实例就是一个目录,在设计上强制在任意时刻,只有一个操作系统进程可以打开bitcask进行写操作,这个进程就可以看作是bitcask服务。在任意时刻,这个目录中只有一个文件是active的,只有这个文件是可以被写入的。当这个active的文件大小达到一个临界值的时候,bitcask就会创建一个新的文件,用来取代当前的active文件。被取代的文件被称为老文件,之后永远都是不可变的,不会再有任何进程往里面写入数据。
当前存活的文件(active file) 只允许追加写(appendinf),这意味着顺序写并不要求磁盘 disk seek,每一个被写入的 entry 非常简单,
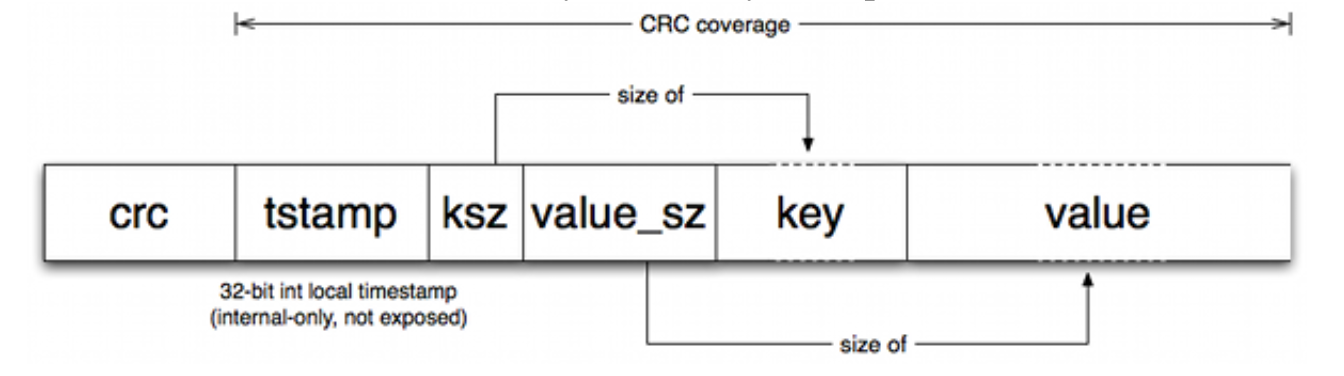
- crc:一个检验值,在这里可以忽略
- tstamp:时间戳
- ksz: key的大小
- value_sz : value的大小。
对于每一个写,一个新的entry追加写到文件中。而删除操作,被看成一种特殊的写操作,它将在merge的过程中删除。

追加写完成之后,一个内存结构keydir 被更新。keydir是一个hash table,key就是插入数据的key,value指向了插入数据value在文件系统中的具体位置。

write 操作:
当一个写操作发生的时候,keydir会自动更新最新数据所在的位置。旧的数据仍然存在磁盘上,但是任何新的读操作都将读取新的数据。
read 操作:
主需要至多一次(more than a single disk seek), 为什么?从内存中的keydir查询key,从这里知道了value所在的file_id,位置,大小,然后只要调用系统的读取接口就行了。一般操作系统都还会有自己独立的disk读缓存,所以这个操作实际上可以更快。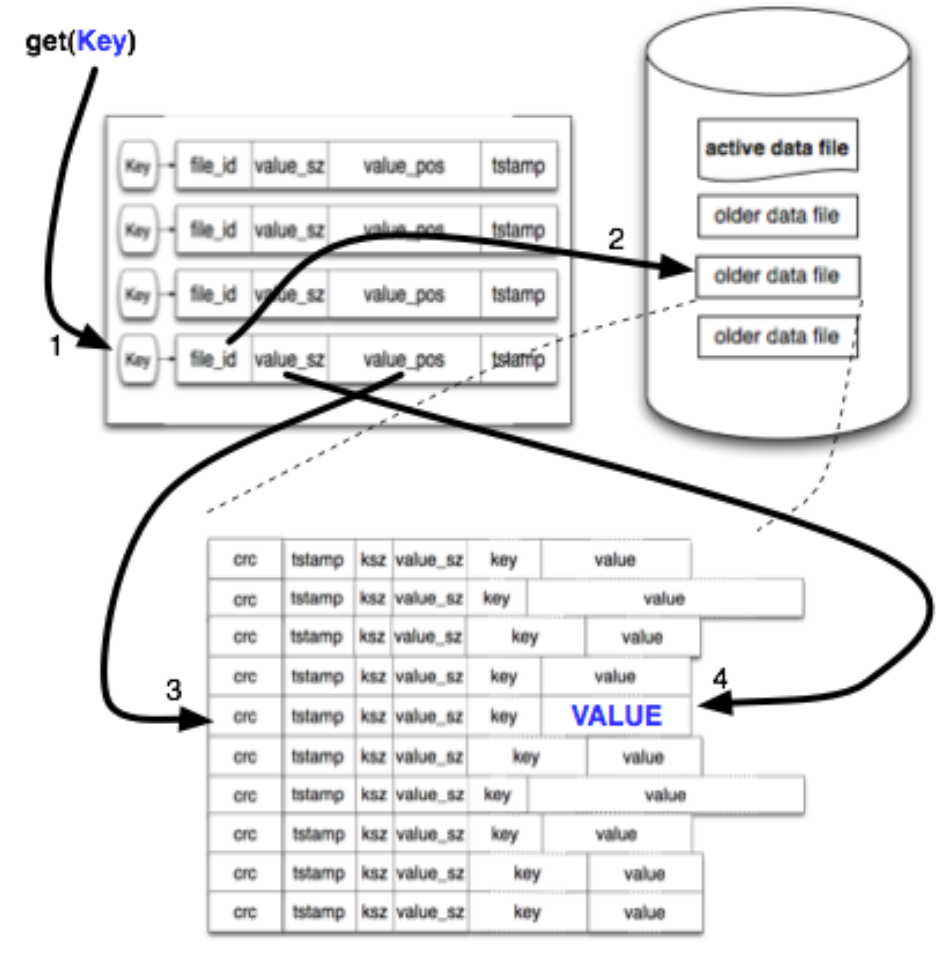
merge 过程:
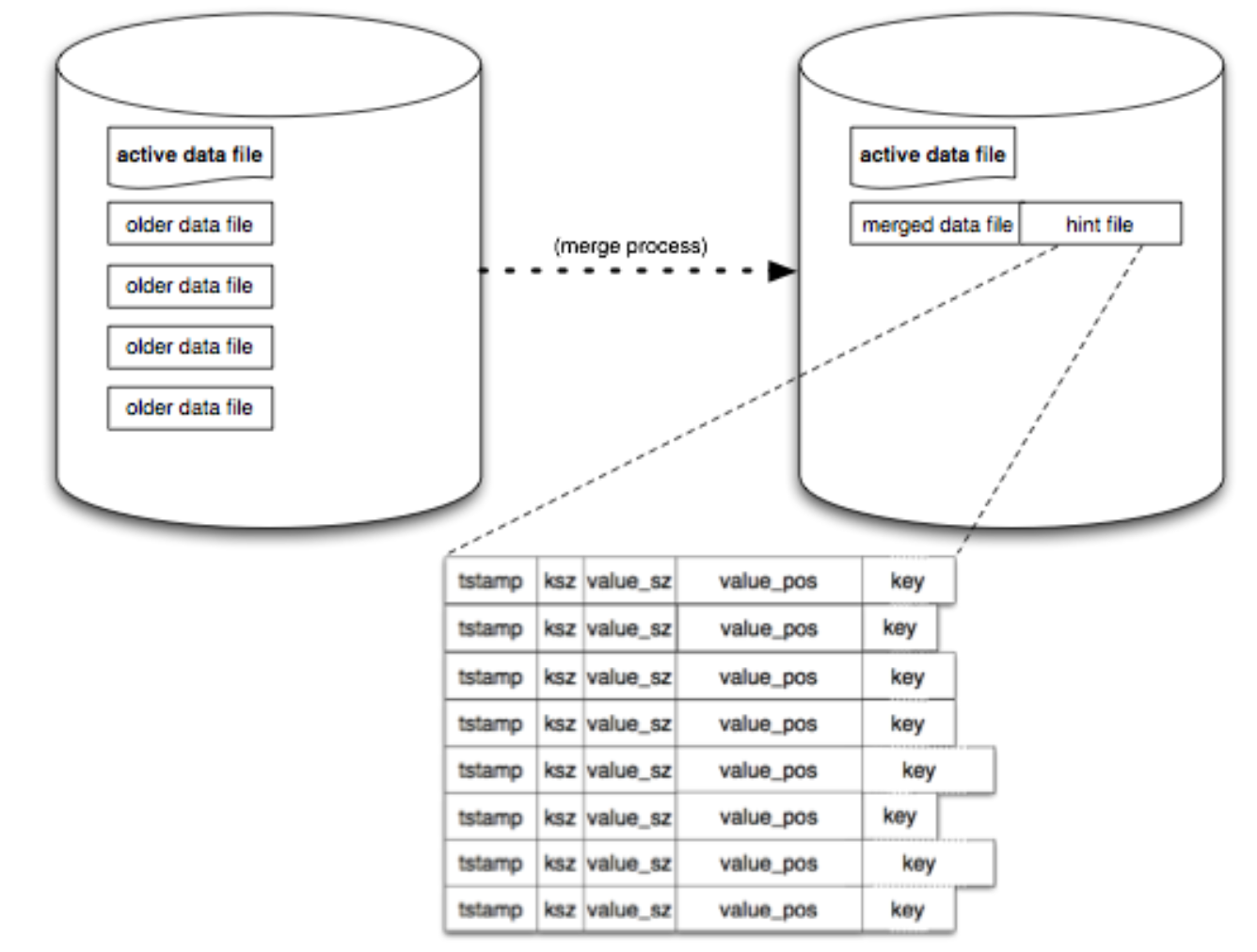
合并进程遍历所有的老文件,产生一个只包含当前最新版本数据的文件。这部分完成的时候,还会产生一个hint file,这个文件本质上和data 文件一样,只不过他们保存的是value所在文件上的位置,而不是value本身。这个文件可以加速从目录文件重建keydir的过程。
Reference
- 本文标题:bitcask 存储模型
- 本文作者:codeflysafe
- 创建时间:2022-04-09 16:53:26
- 本文链接:https://codeflysafe.github.io/2022/04/09/bitcask/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!